
Multimodal Apps Workshop

Introduction
Most computers come standard with a microphone, speaker, and a webcam. We use them in pretty standard ways, for video conferencing, maybe the occasional photo booth giggle. They're not considered inputs or outputs for most apps.
Instead, if you're using software, your interactions are limited to touches, swipes, keystrokes, maybe some frantic mouse clicking. These interactions aren't natural. They demand concentration and focus to the point users hold their breath when interacting with your software.
Computer vision, speech recognition, and speech synthesis are not new ideas. They're not even new machine learning ideas. Most people have had the experience of a smart assistant like Siri misunderstanding a request. What is new is that we soon may have cheap enough, fast enough, and good enough AI that can reason about these inputs together and provide a foundation for a new interaction paradigm.
In my workshop titled Omni Apps – Designing for Apps That Can See, Hear, and Speak, we explore this idea. I had the pleasure of running the workshop for designers in Naarm at Design Outlook 2024. Here are my reflections on the workshop and the input from the amazing participants.
Format

For this workshop, I designed and built 3 interactive prototypes and housed them in a app called Omni playground. The prototypes are features from my open-source meal planning app Omnivore. I wanted to try and trigger the same self-reflection that I've experienced designing and using the software, for an audience that may not want to try and run an open-source app on their computer.
Each prototype would allow the workshop participants to see the inputs and outputs to the model, and a related user interface, to help contextualize the experience. We used Airtable in the workshop to log all the participants' activity. This helped aggregate data for the session, which we could discuss!
Prototype 1 – Vision

The first prototype was based on Vision, and looked at GPT4o's ability to parse a photo of a recipe and turn it into a user interface. Here's a video demo of the feature in Omni Playroom.
For this activity, I ensured we had a varied collection of recipes, languages, typography, and publishing years. I encouraged students to tweak the prompt to modify the output of the scan. Say to double a recipe's quantities or convert into different units, or even different languages.
The feedback from this round was that participants were impressed with how accurate the vision parsing was, and its capacity to translate. We discussed how slow the vision model was, taking 8-10 seconds. Participants were soon tweaking the prompts, to influence the recipe's markdown and how it expressed the recipe steps or the formatting of the ingredients. One participant noted that GPT4o had made choices that perhaps they'd prefer input on. Would it be possible for the AI to interrupt and identify that a clarification was needed?

When asked if they could trust the output, most participants remarked they still hesitate when preparing the recipe. Participants wouldn't want to waste food or spoil their cooking. It was also noted that in the UI there's no way to compare the instructions to the source material.

I think with this prototype we established that computer vision via GPT4o is very general purpose, can be guided, and has reasonable alignment for this task. But the more complex the task we give it, the less likely we are to trust it.
GPT4o – Omni

A key topic of the workshop was the recently announced GPT4o. OpenAI have positioned GPT4o as a cheap, fast and good enough omnimodal AI, powering exciting demos with an assistant that can appear to see, hear and speak in a what is observed to be a very organic way from the demos they've shared.
Omnimodal isn't a common way to describe AI models, but I think it's a very useful term that's worth grappling with, so much so I named the workshop after it. What I think OpenAI is expressing is that the model can natively reason about audio, images and text inputs, as well as natively outputting images, text and audio in one inference call.

To achieve the same experience today, you need to use four separate models (speech to text, GPT4, text to speech and the unreleased voice engine), and all the extra latency and costs that would come with it. Until we get our hands on the full spec + API for using GPT4o it's hard to evaluate!
The challenge I put to the participants is that we as designers have a key role to understand the trade-offs for every OpenAI API call. Is it fast enough, is it cheap enough, and is it good enough were 3 questions we need to answer during our iterations.
A good analogue is the early days of the web: was a web page fast enough to download, was our data inexpensive enough, was the content worthy of the cost and time invested? This was something users evaluated per click! Now we take fast and cheap web pages for granted, and have a good eye for what a quality link is. Helping educate our users on this is a really important challenge for designers.
Prototype 2 - Vision + Speech to text
The 2nd prototype was primarily based on Vision again, this time from a webcam input.
Participants had access to a pile of Lego animals and objects. They were instructed by me to add the Lego piece to the shopping list as a shopping item via the text or voice to text interface. Then we'd use the webcam to take a photo of the lego item, and see if the vision model would detect it in the shot and correctly tick it off the shopping list.
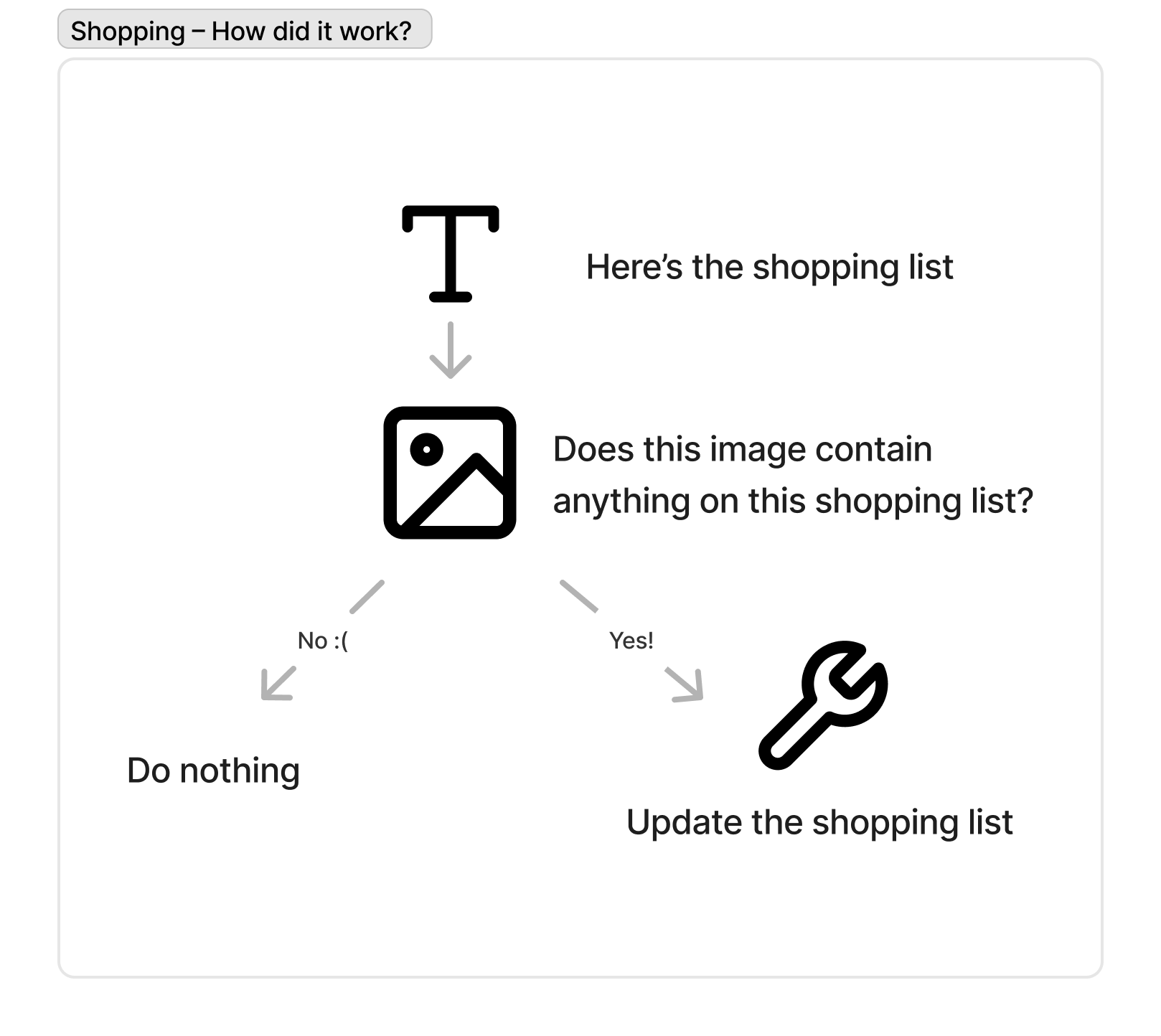
You can see in the video demo above, detection didn't always work. Your result would vary widely depending on what object you selected, the angle, and what else was in frame.
There was a mistake in my configuration of the prototype. If you just added "cake" to the shopping list, instead of "lego cake" the workflow would turn it into a list of cake ingredients based on my prompt. This was a handy feature in Omnivore, but not handy in this context as it generated lots of shopping list items, none of which would match as intended to the Lego cake the participant had on hand.
It was bit embarrassing, but a great example to discuss how this is an inherent challenge with AI, that the output is not deterministic, and with different user inputs, you can get very different outputs.
Other discussion points related to speed.
The speed of it means that honestly I'd prefer to just manually tick the checkbox. It also took a bit of effort to align the product and the camera correctly
Cost was also raised as an issue. While we could use the webcam to take many pictures every few seconds to allow the app to "see" and reason, it would be a bit pricey for this use case, where checking off a checklist is quite a fast interaction.
I was really happy with this observations from the group. I liked how participants got to see first hand a use case that probably didn't met our trade offs. This feature isn't fast enough, good enough or cheap enough to make sense for our app – even though it's possible.
Prototype 3 - Hearing and Speaking
The 3rd prototype was based on speaking and hearing. There's no audio in this clip unfortunately.
Participants were encouraged to form a group and interact with the assistant together.
Because GPT4o does not yet have audio input and output, we used VAPI to help create a useful voice assistant, with low latency and speech detection. For the workshop, I selected the Eleven labs voice "Maya" which was an Australian female voice.
I encouraged the users to change the associated system prompt for the assistant. With limited time to experiment, most participants found they were unable to affect the tone, emotion, and expression just via a system prompt. Directions like "Be more angry" or "Be mean" did not translate effectively.

We discussed this as a limitation of the pipeline of models powering the interaction. Going from a GPT4o response to a separate text-to-speech model is a lossy process. Your chosen text-to-speech model may be fine-tuned to always be pleasant in tone.
GPT4o demos show that an omnimodal approach might be key to unlocking the human-like expressiveness we seek in conversational experiences.
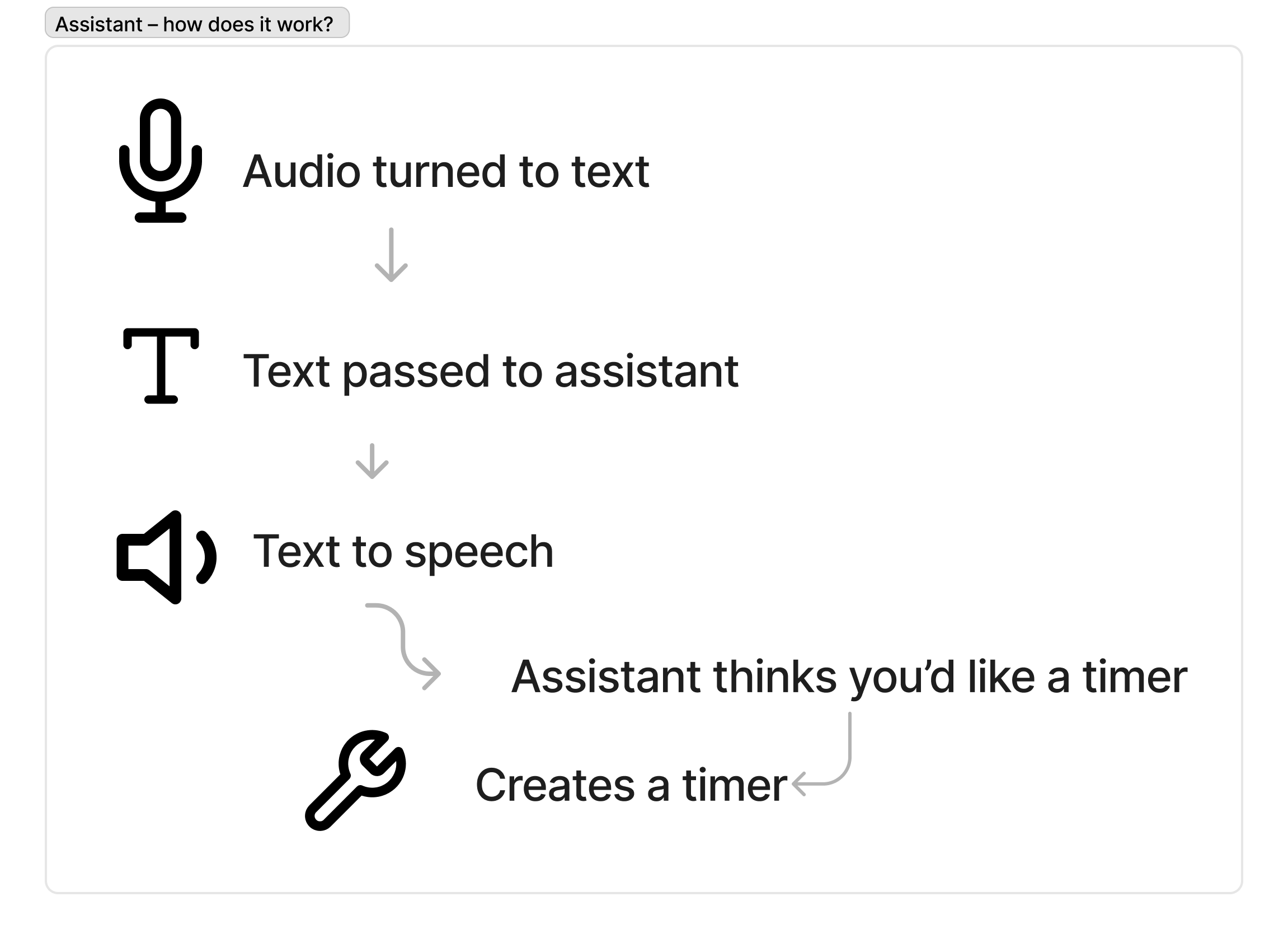
Participants were able to invoke a timer using function calling. This worked well because the assistant was able to invoke the timer included in the recipe.

Conclusion
The question that most participants asked after the workshop was about the playground, and how they might continue this workflow. My suggestion was to create an OpenAI developer account, and then they could experiment with prompts using OpenAI's playground, which is a generic UI for using many of the APIs. If you have or know a better tool, let me know!
Throughout the workshop, we modeled this workflow of collecting data on our responses, reviewing and then rating the responses, and iterating the prompt with our data logged in Airtable. I see this as very expressive of a design methodology, totally compatible with design practices like discovery, user testing, and iteration. This is especially relevant where designers will ultimately need to engage with users to help evaluate the cost, speed, and accuracy of the responses.
I'm very thankful for the participants' time. I couldn't have asked for a more positive and engaged group of workshop participants. I think I was successful in generating big questions in the mind of each participant, and hopefully encouraged them to think about their own design practice going forward.

Aside – On Figjam
I ran the workshop out of Figjam, which was the first time I've done that for an in person class. It went really well, and encourage you to try it.
- All participants had spaces to post reflections and questions that I and other participants could engage with. Not just the participants confident enough to ask a question out loud.
- Being able to reflect on their comments post-workshop has been very helpful for authoring this post
- I had a main track of slides, and then asides for content that we didn't have time to talk about in class. I could also add material during the class, as participants asked me questions. I would use the Tab key to jump between slides. Students could also follow me on their screens.
- I had little time reminders across the Figjam, which helped me adjust the pace and ensured we kept to time.
- It helped that all the participants were comfortable using Figjam, with some design background.
Figma have just launched a slides product, but I'd thought I'd detail how I used Figjam all the same incase you want to try it yourself.